Car rental problem
I'd like to present to you the problem I stumbled upon in the R. Sutton and A. Barto book about reinforcement learning and really liked. You manage two locations for car rental and try to maximize your profit by moving available cars around locations. It can be seen as a very close model to the real-world situation. It is also very convenient to show how to approach and solve such problems in terms of the RL.
Original text:
Car rental problem
Jack manages two locations for a nationwide car rental company. Each day, some number of customers arrive at each location to rent cars. If Jack has a car available, he rents it out and is credited 10 dollars by the national company. If he is out of cars at that location, then the business is lost. Cars become available for renting the day after they are returned. To help ensure that cars are available where they are needed, Jack can move them between the two locations overnight, at a cost of 2 dollars per car moved. We assume that the number of cars requested and returned at each location are Poisson(\(\lambda\)) random variables. Suppose \(\lambda\) is 3 and 4 for rental requests at the first and second locations and 3 and 2 for returns. To simplify the problem slightly, we assume that there can be no more than 20 cars at each location (any additional cars are returned to the nationwide company, and thus disappear from the problem) and a maximum of five cars can be moved from one location to the other in one night. We take the discount rate to be \(\gamma\) = 0.9 and formulate this as a continuing finite MDP, where the time steps are days, the state is the number of cars at each location at the end of the day, and the actions are the net numbers of cars moved between the two locations overnight.
The notebook for the article is available at .
Mathematical formulation
Let's rewrite the problem in RL terms. Then we will use the value iteration to find optimal value function \(V(s)\) and policy \(\pi(s)\).
Our state here is \(s = (n_0, n_1)\) for cars at location 0 and location 1 at the end of some day. Then we take action \(a \in -5, \ldots, 5\) and at the start of the next day we have \((n_0 - a, n_1 + a)\). Note that some actions are pointless or incorrect for some states, e.g. \(s = (2, 1)\) and \(a = 5\). For these cases we will add a terminal dummy state with zero reward. All pointless/incorrect \((s, a)\) pairs will transition to it with probability one.
After, we have some realization of poisson rental requests \((\text{req}_0, \text{req}_1)\) and returns \((\text{ret}_0, \text{ret}_1)\) for each location. Note that the reasonable values for rental requests are \(0, \ldots, n_0 - a\) and \(0, \ldots, n_1 + a\). That's why we can truncate poisson random variables to their maximum values. The probability of all values greater adds to the probability of the maximum value. Having the request values, the reasonable values for returns are \(0, \ldots, 20 - (n_0 - a - \text{req}_0)\) and \(0, \ldots, 20 - (n_1 + a - \text{ret}_1)\). So returns are truncated as well. The final state is $s' = (n_0 - a - \text{req}_0 + \text{ret}_0, n_1 + a - \text{req}_1 + \text{ret}_1) $. To compute probability of such a transition we use independence of the requests and returns so their mutual probability is a product of individual probabilities. Overall, we can compute \(p(s' | s, a)\) by fixing \((s, a)\) and iterating over reasonable realizations of \((\text{req}_0, \text{req}_1)\) and \((\text{ret}_0, \text{ret}_1)\), adding \(\mathbb{P}(\text{req}_0, \text{req}_1, \text{ret}_0, \text{ret}_1)\) to corresponding \(s'\).
Reward \(r(s, a, s')\) here is a random variable for fixed arguments because it depends on the random requests and returns. To use it in the dynamical programming we need to average it over valid \((\text{req}_0, \text{req}_1, \text{ret}_0, \text{ret}_1)\) for given \((s, a, s')\). We can do it during the same iteration when computing \(p(s' | s, a)\). We init \(r(s, a, s')\) with zeros. Then, for fixed \((s, a)\) and realization of the requests and returns the reward is uniquely determined. We multiply it with the probabilty of such realization and add to \(r(s, a, s')\). After all iterations we have completed \(p(s' | s, a)\) and averaged \(r(s, a, s')\) but unnormed. The normalization constant for averaging is exactly \(p(s' | s, a)\).
To compute optimal value function and policy we will use value iteration algorithm which basically solves the following equation iteratively:
The optimal policy is then obtained as
Implementation details
Note
The source code is available at components.py. Here we outline the main parts of the computations.
We init five dimensional tensors for probability and reward:
We then iterate over all starting states and actions, then over all reasonable rental requests. In the inner-most cycle the reasonable return requests are easily determined as well as their probabilities.
We also compute probabilities of the truncated poisson variables for the retuns. Their mutual probability can be computed via np.outer. The reward is constant in the inner-most loop because it depends only on the action and the rental requests. Finally, we add up probaility and mean reward to all possible states we transition to under current realizations of the poisson variables.
After all loops we normalize average reward as was said:
Can we do without loops?
Here we use nested loops as the most intuitive approach. We can't just use vectorized operations because these operations highly depend on the inital state, action and requests. Only in the inner-most loop we vectorize operations with returns. Can you think of a faster solution?
In the value iteration we flatten state dims so our tensors will have three dimensions \((s, a, s')\). It is convenient to use np.einsum to compute mean values over probability transition function:
from scipy import linalg
def value_iteration(
reward_t: np.ndarray,
prob_t: np.ndarray,
gamma: float,
v0: np.ndarray,
tol: float = 1e-3,
max_steps: int = 1000
) -> np.ndarray:
# compute avereged over s' reward r(s, a, s')
reward_expect = np.einsum(
"iaj,iaj->ia",
prob_t, reward_t
)
v_prev = v0
for _ in range(max_steps):
v_expect = np.einsum(
"iaj,j->ia",
prob_t, v_prev
)
v = np.max(reward_expect + gamma * v_expect, axis=-1)
delta = linalg.norm(v - v_prev, np.inf)
if delta < tol:
break
v_prev = v
return v
Results
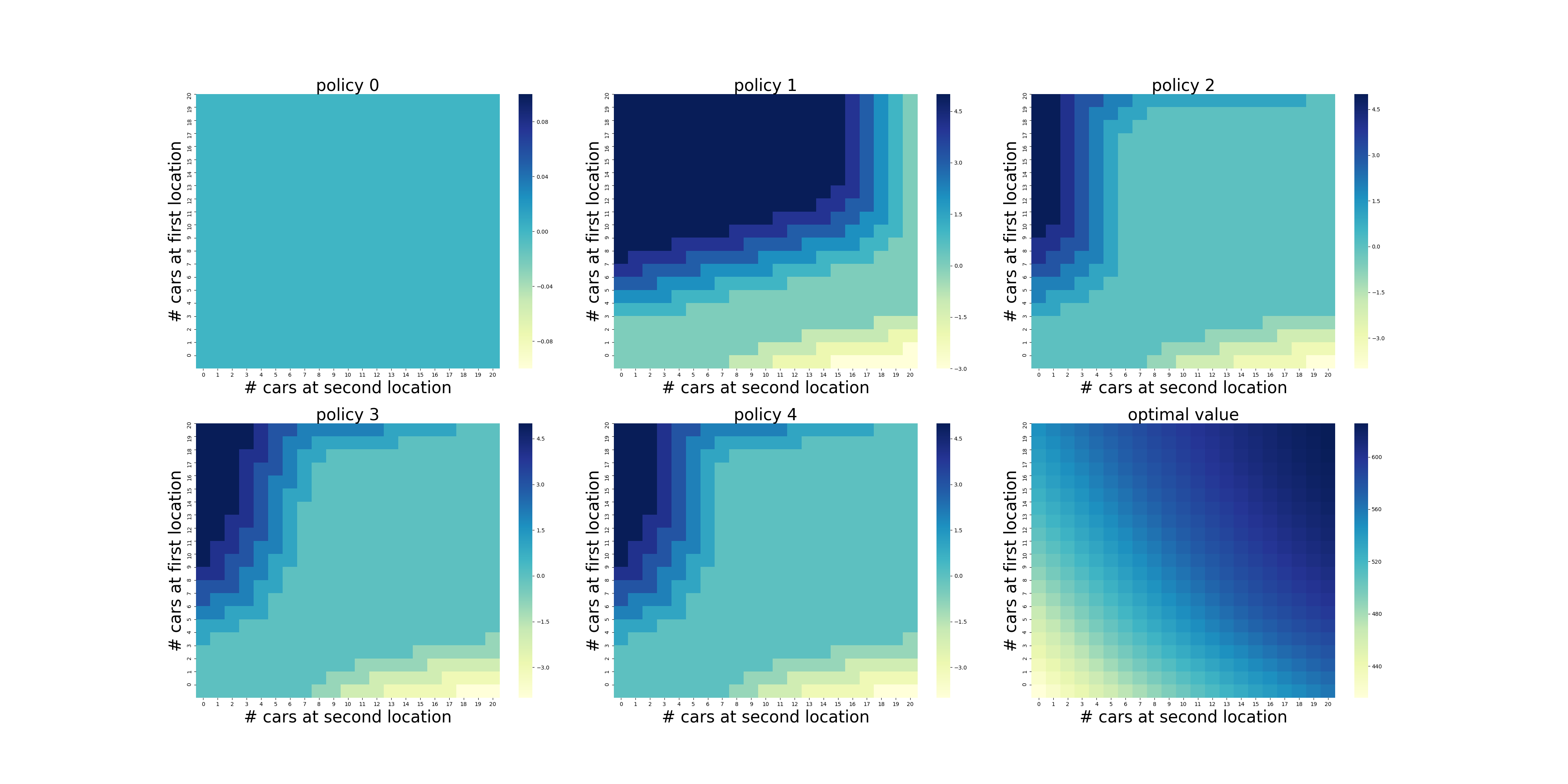
The found optimal value function and optimal policy are illustrated below. The results match with book's illustrations.
{kind=link}
In the optimal policy we see the reasonable tendency to balance number of cars in the locations. Because the rental request rate in the location 1 is higher we are more willing to move cars there and less willing to move it in other direction.
Advanced problem
The book has also modified version of the task.
Quote
One of Jack’s employees at the first location rides a bus home each night and lives near the second location. She is happy to shuttle one car to the second location for free. Each additional car still costs 2 dollars, as do all cars moved in the other direction. In addition, Jack has limited parking space at each location. If more than 10 cars are kept overnight at a location (after any moving of cars), then an additional cost of 4 dollars must be incurred to use a second parking lot (independent of how many cars are kept there).
To solve it we only need to take into account the new details when computing \(r(s, a, s')\). All the rest stay the same. Updated computation of the tensors is located at components_adv.py. The results are illustrated below.
Here we see how we adapt to the new environment. For example, we use the free ride to balance number of cars at the locations when previously it was too costly. We have also become very selective in the number of cars moved to pay for additional parking only in one location. The value function has become unlinear.